
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- R
- scanpy
- Python
- 통계학
- 주식
- bioinformatics
- Preprocessing
- bcftools
- 고공 바이오 데이터베이스
- liver
- scRNASeq
- fastqc
- 대학원
- single cell rna sequencing
- ngs short
- Tutorial
- 대학생주식
- 데이터베이스 소개
- np.diagflat
- Next Generation Sequencing
- 후기
- numpy
- 대학생재테크
- 공공바이오데이터베이스
- NGS
- 유전체데이터베이스
- 주식투자
- 티스토리챌린지
- 오블완
- 선형대수
- Today
- Total
biotechknowledge
공공바이오 데이터베이스 - 유전체 데이터베이스 본문
유전체 개요
체학(-ome):
분자들이나 세포 등과 같이 어던 대상의 집합체 전부
Seq:
시퀀싱(sequencing) 기술로 생산된 데이터
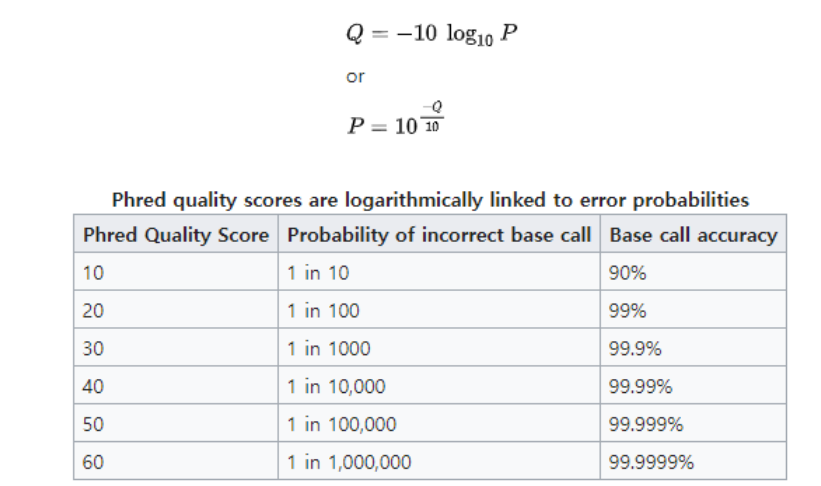
DNA서열의 퀄리티
모든 시퀀싱은 DNA 염기, 각 여기의 오류(정확도) 확률 정보 생산
DNA 데이터베이스 : GenBank
미국의 NCBI의 DNA 서열 공개 데이터베이스
주석이 된 핵사 서열(핵산에서 유래된 단백질 서열 포함)
현재 약 50만 생물종 이상에서 유래된 핵산 서열을 보유하고 있음 (1차 DB)
생물종, 기능, 연구분야 등으로 구분된 21개 division 으로 구성

GI Number('gi') :
NCBI 가 자체적으로 각 서열에 대해서 연속적으로 부여하는 번호('GenInfoNumber')
'Accession.Version number' :
1999년부터 INSDC에 의해서 공식적으로 발행하는 서열의 등록번호
DNA 데이터베이스 : SRA 개요
High-throughput sequencing의 공개 데이터베이스 (1차데이터베이스)
대부분 jornal에서 NGS데이터를 SRA에 저장하도록 함

DNA 데이터베이스 : dbSNP
sbSNP 핵산변이(nucleotide variation) 데이터베이스 (1차 데이터베이스)
SNP 뿐만 아니라 small INDEL, microsatellite, short tandem repeat 등
핵산 변이 정보, 5' 및 3' flanking sequence, 유전자형(genotype), 빈도(frequency)를 포함
새롭게 발견된 SNp 가 dbSNP에 전달되면 ssID 부여, ss#가 큐레이션 후 최종적으로 확인되면 rsID를 부여
같은 위치에 여러 개의 ssID가 있을 수 있지만, rsID는 한개만 존재
바이오 빅데이터의 무결성 검사
데이터 무결성:
데이터가 우연하게 또는 의도적으로 변경되거나 파괴되는 상황에 노출되지 않고 보존되는 특성
데이터의 정확성과 일관성을 유지하고 보증하는 것을 가리키며 데이터베이스나 RDBMS 시스템의 중요한 기능
데이터 무결성 확인 : MD5 checksum
전체 데이터를 512 bits 단위(message block)으로 나누어 hash 값을 구한다.
1 bit 만 차이가 나도 hash 값이 전혀 다른 값이 된다.
'bioinformatics' 카테고리의 다른 글
| 공공바이오 데이터베이스 - 전사체 데이터베이스 (0) | 2025.09.06 |
|---|---|
| 공공 바이오 데이터베이스 - 바이오 데이터 소개 (0) | 2025.08.21 |
| [NGS]SAM/BAM ~ align ~ tablet/VCF format (0) | 2025.05.10 |
| [NGS]Fastq 전처리 방법과 소프트웨어 (1) | 2025.05.08 |
| FASTQ format 개념, NCBI 데이터 다운로드 하는 방법 (0) | 2025.05.07 |



